
発売当初,Field Reports の性能測定を行い結果をブログで公開しました。
Field Reportsは中小規模システム向けの帳票ツールなので,元々大量ページの出力はあまり考慮していませんでした。そのため以前の性能測定では,1,000ページまでの測定にとどめています。しかし,1,000ページを超えた領域での性能については,ずっと気になっていました。
最近,10,000ページを出力したいというお客様からのお問い合わせがありましたので,この機会に1,000ページ以上を出力した時の性能測定を行いました。
性能測定 (1)
下表の環境で性能測定を行いました。
以前の測定環境とは異なりますので,ご注意ください。
| PC | NEC Express 5800 110Gd |
|---|---|
| CPU | Core 2 Duo 1.86GHz |
| Memory |
8 GB |
| OS | CentOS 5.7 |
| 対象ソフトウェア | Field Reports for Linux 1.3.0 |

図のような見積書をイメージした帳票を生成する時間を測定します。
ページ数を引数で変更できるようなスクリプトを作成し,1, 10, 100, 500, ... , 10,000 とページ数が変化した時の処理時間を測定しました。
処理時間として,timeコマンドの“real”を用いています。
測定結果を以下の表とグラフで示します。
| ページ数 | 処理時間(秒) |
|---|---|
| 1 | 0.20 |
|
10 |
0.66 |
| 100 | 6.99 |
| 500 | 65.92 |
| 1,000 | 218.13 |
| 2,000 | 793.70 |
| 3,000 | 1,691.43 |
| 4,000 | 2,972.59 |
| 5,000 | 4,774.46 |
| 6,000 | 6,943.57 |
| 7,000 | 9,523.57 |
| 8,000 | 12,412.86 |
| 9,000 | 15,560.13 |
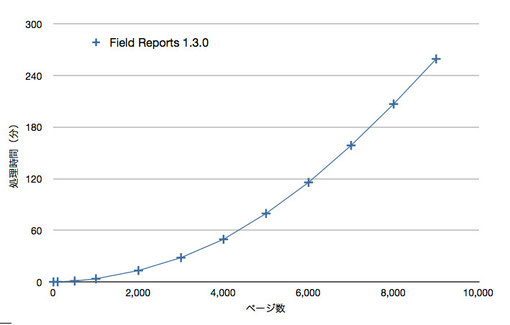
結果分析 (1)
9,000ページで約4時間20分かかり,10,000ページまで実施できませんでした。5時間を軽く超えそうです。
処理時間をページ数の二乗で割ると,1,000ページ以上ではほぼ一定値になりますので,N^2オーダーの処理になっていることがわかります。
チューニングの実施
この結果にはちょっと納得がいかなかったので,パフォーマンス・チューニングを試みました。
各処理の区切りでログを出力し,ボトルネックになっている処理を絞り込み,以下の改善を地道に行いました。
- 可能であれば,ループの内側で行なっている処理をループの外側に追い出す。
- 再帰処理をすべて末尾再帰の形に変形する。
- 連想配列の検索処理をハッシュ検索に変更。
結果的には,最後のハッシュ処理への変更が一番効きました。
性能測定 (2)
チューニング後の測定結果を以下の表とグラフで示します。
| ページ数 | 処理時間(秒) |
|---|---|
| 1 | 0.16 |
|
10 |
0.49 |
| 100 | 4.33 |
| 500 | 25.63 |
| 1,000 | 61.00 |
| 2,000 | 180.56 |
| 3,000 | 352.22 |
| 4,000 | 497.82 |
| 5,000 | 718.37 |
| 6,000 | 979.07 |
| 7,000 | 1,263.94 |
| 8,000 | 1,627.46 |
| 9,000 | 2,036.81 |
| 10,000 | 2,676.58 |

結果分析 (2)
グラフから明らかなとおり,劇的に性能が改善しました。
チューニングの結果,N^2のオーダーから N×log Nのオーダーに下がったようです。
PDFの生成には木構造のデータを大量に扱いますので,妥当な結果になったと思われます。
このパフォーマンス・チューニングの成果は,次の1.4版には反映させたいと思います。